Xorro P2P 是由三位軟體工程師開發的迷你bittorrent檔案分享系統陳欣俞(Ken Chen), David Kurutz, and Terry Lee.
近年來去中心化(decentralized)的各項主題持續發燒, 如Bitcoin, Blockchain and IPFS等. 我們團隊對於此議題相當有興趣, 想開發此主題之專案來加深我們對於系統設計, 程式語言以及團隊合作的能力 經過研究後, 決定以Ruby從頭實作一套Bittorrent(BT)-like的系統. 目前版本為測試版本, 功能有完整的分散式路由表, 節點間的溝通和基本的檔案傳輸. 在本頁最後列出未來欲新增的功能, 將以這些方向持續改善此專案.
此網頁是我們在開發Xorro P2P的歷程和故事. 希望讀者閱讀後對P2P系統能有更深一層的認識
目錄
歷史與回顧
作為一個P2P系統的開發者, 我們必須去研究及了解P2P相關歷史及系統組成. 我們所做的搜集和閱讀P2P網絡的相關資料, 從舊到新有: Napster, Gnutella, Freenet, BitTorrent, IPFS...
中心化系統 vs 去中心化系統
第一個最重要的概念就是了解中心化和去中心化系統的不同. 由比較第一代和第二代的網絡架構, 可以幫助我們去描述這兩者間的不同.
Napster: 中心化系統
最早知名的P2P系統可以追朔到1999-2000年, Naspter的出現. Naspter是一個主要專注於音樂檔案的檔案分享系統. 註冊用戶在Napster最高峰期有8000萬人.
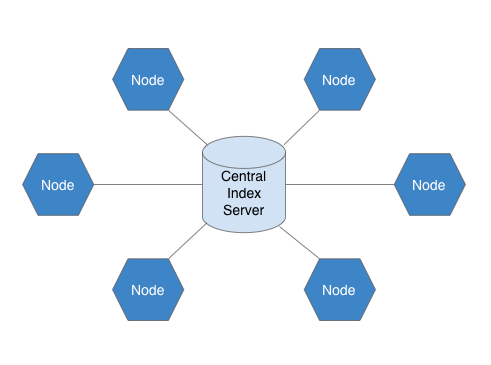
連接到中央索引伺服器, 此伺服器知道所有節點持有的檔案為何.
因為其本身為中央化的結構, Napster中央伺服器很容易遭受攻擊以及檔案傳送備受爭議, 營運兩年後在法院判決下被迫關閉, 除此以外, 也有像是單點失效和缺少擴展性的問題存在.
BitTorrent, Gnutella, Freenet: 去中心化系統
下一個世代的P2P網路像是: Gnutella, Freenet 和Bittorrent這些以分散式為基礎的應用可以有效避免中央化存在的限制和問題發生.
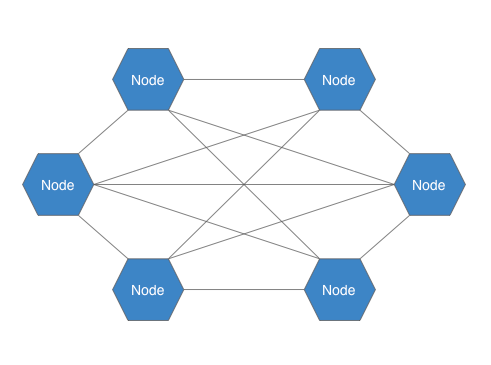
在一個去中心化的系統像是Bittorrent, 每個電腦/節點都同時是客戶端及伺服器, 管理著自己的檔案索引片段. 節點們可以藉由其他節點來找尋檔案的位置, 免除對中央伺服器的依賴.
P2P檔案系統的深入介紹
暸解了新一代P2P系統的優點後, 接下來我們將要更近一步來介紹它們的特色. P2P網路已經是發展一段時間的技術, 有許多資源可供我們研究和查詢. 其中分散式雜湊表(ditributed hash tables, DHTS)是P2P網路中最重要的一項技術, 在專案開始進行前為確保我們對於這系統有深刻的了解, 我們團隊花許多時間在閱讀及研究白皮書, 文獻, blog和Stackflow問答.
In addition to white papers, we relied on specification documents, various blog posts and StackOverflow answers.
如果你想知道更多資訊, 可以點選resources來查看參考資料
重要特色
Bittorrent特色
經過比較許多P2P網路系統後, 我們最後聚焦在這某幾項在Bittorrent所擁有的特色, 用來完成初版的application. 每一項目都會在接下來的章節有詳細的描述.
- 分散式雜湊表
- 檔案分割
- 節點同時為客戶端和伺服器
Demo
進入Xorro P2P 實作細節之前, 用這動畫來展示檔案下載的過程
首先, 清單(即BT的種子, 後面即稱為種子)會被下載, 接下來依據在種子表中的檔案片段信息開始下載各檔案片段(file shard). 當所有檔案片段被下載後, 將會合併回原來的檔案
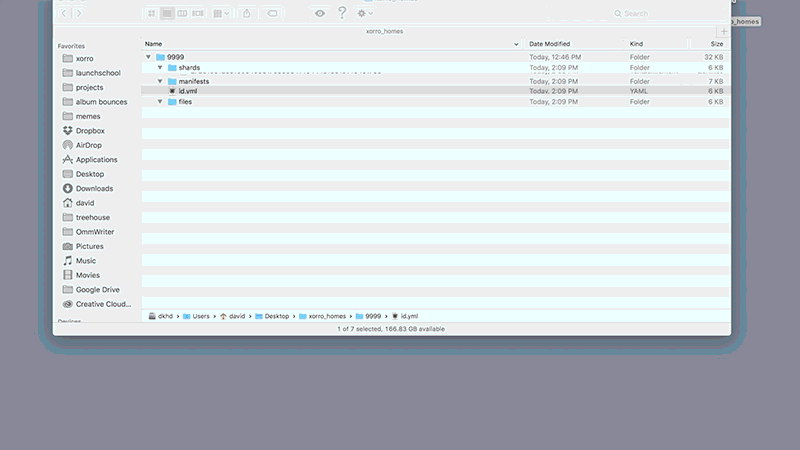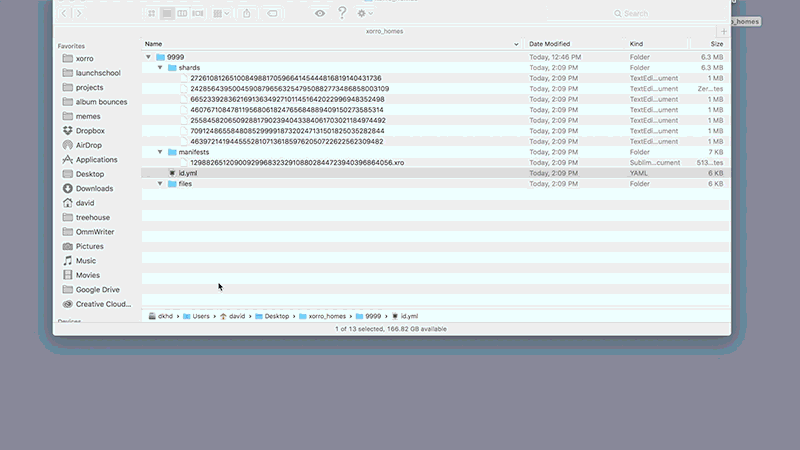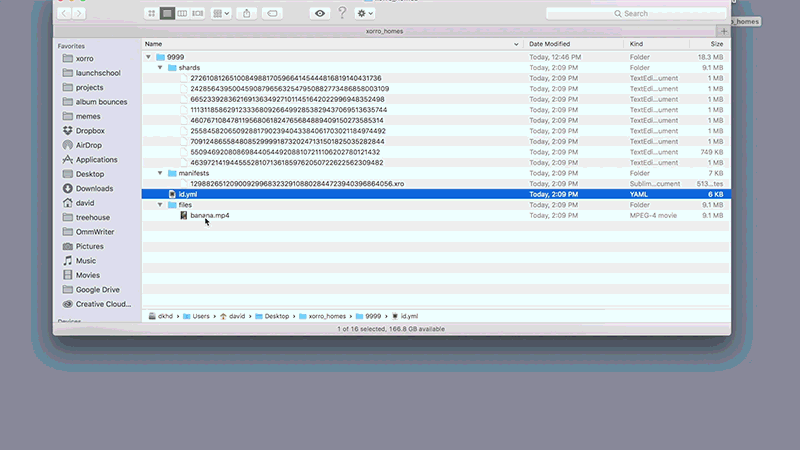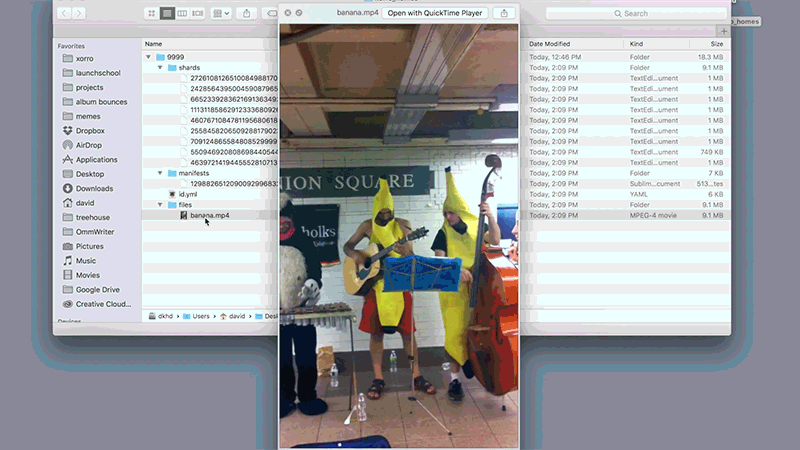
如何實作分散式雜湊表
先評估幾種不同的分散式雜湊表(ditributed hash tables, DHTS)優缺點後: Chord, Pastry, Apache Cassandra和Kademlia, 再以此為考量作為我們選擇執行的依據. 我們最後決定就其普及率, 最簡單的RPC和自動化傳播聯絡資訊等優點, 選擇Kademlia
由於大量的新概念: 節點(node), 路由表(routing tables), K桶(k-buckets), xor distance, routing algorithms, 遠端程序呼叫(remote precedure calls)讓實作Kademlia比想像中的還困難. 雖然在網路上已有些許以Ruby實作的案例, 但我們只依據白皮書和規格表來從零開始建構我們的分散式雜湊表.
Kademlia
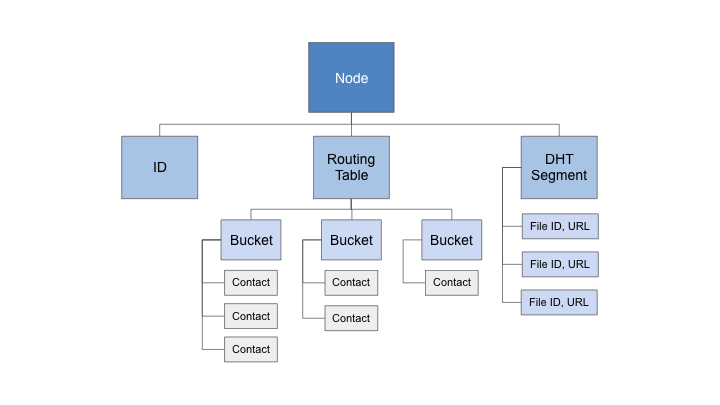
一個Kademlia網路中包含許多節點.
每一個節點都有:
- 獨特的160位元ID
- 包含其他節點聯絡資訊的路由表(Routing table)
- 持有檔案的分散式雜湊表(往後我們稱此為DHT segment, 因其相對於整個網路來說是一小片段)
- 藉由4種遠端程序呼叫(Remote Procedure Call, RPC)來和其他節點聯絡
路由表中包括許多K桶(k-buckets), 每一個K桶都包含了與自身相距一個特定距離的聯絡資訊(contact), 我們會在後面更詳細介紹關於距離的概念.
每一個聯絡資訊都包括了其他節點的ID, IP地址, 通訊埠(port).
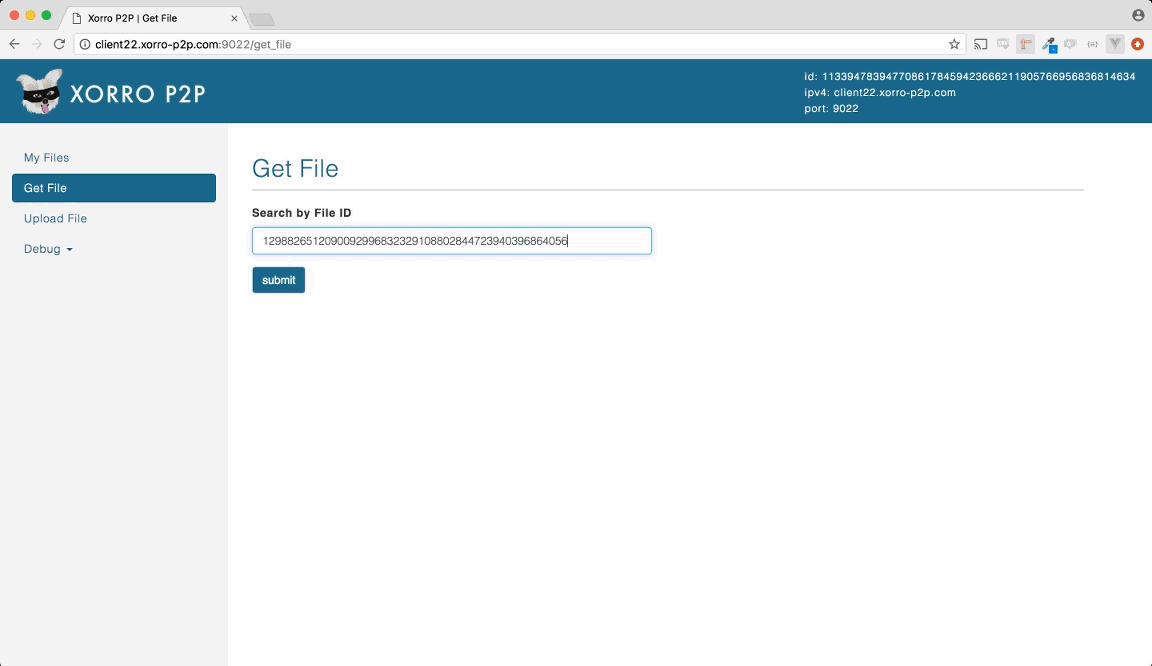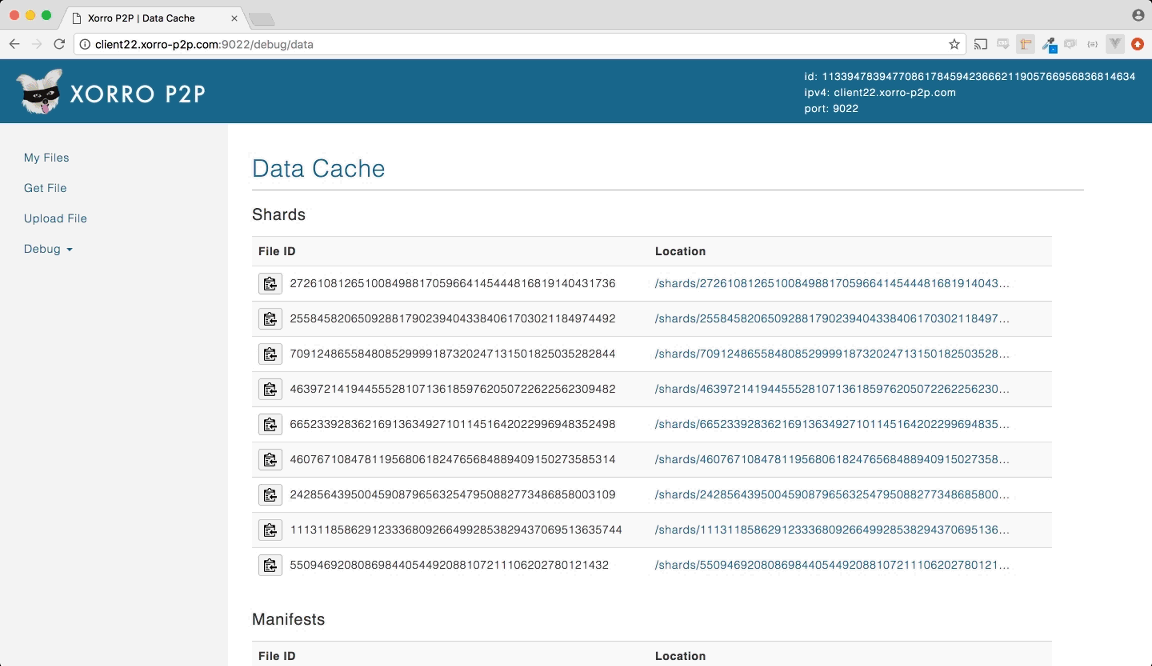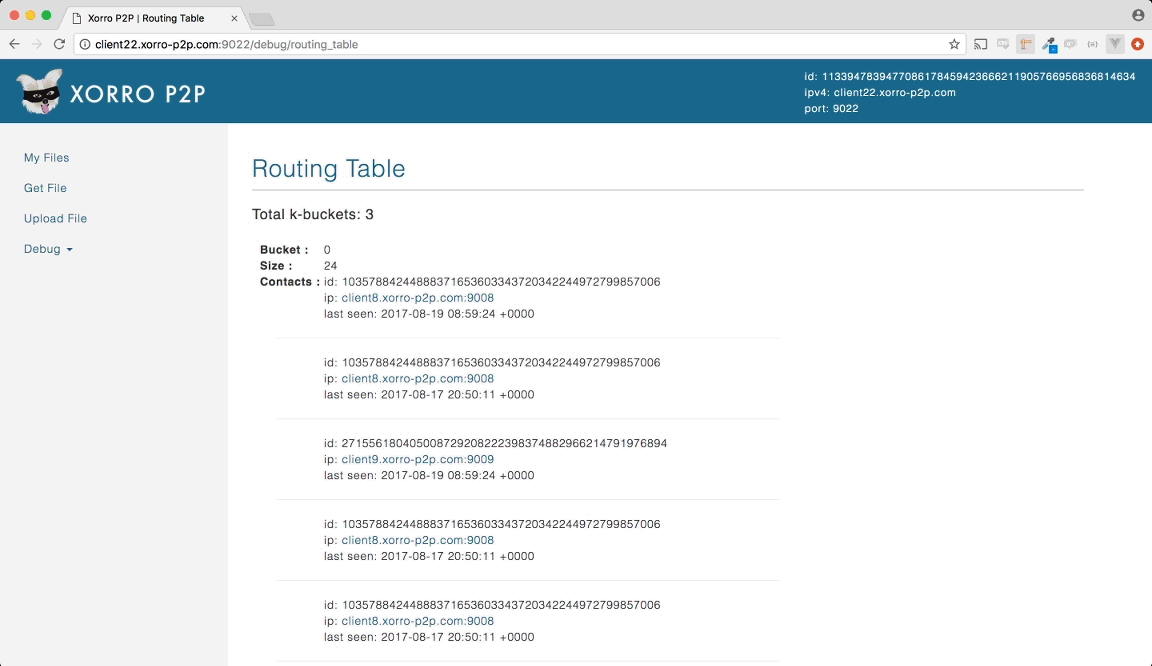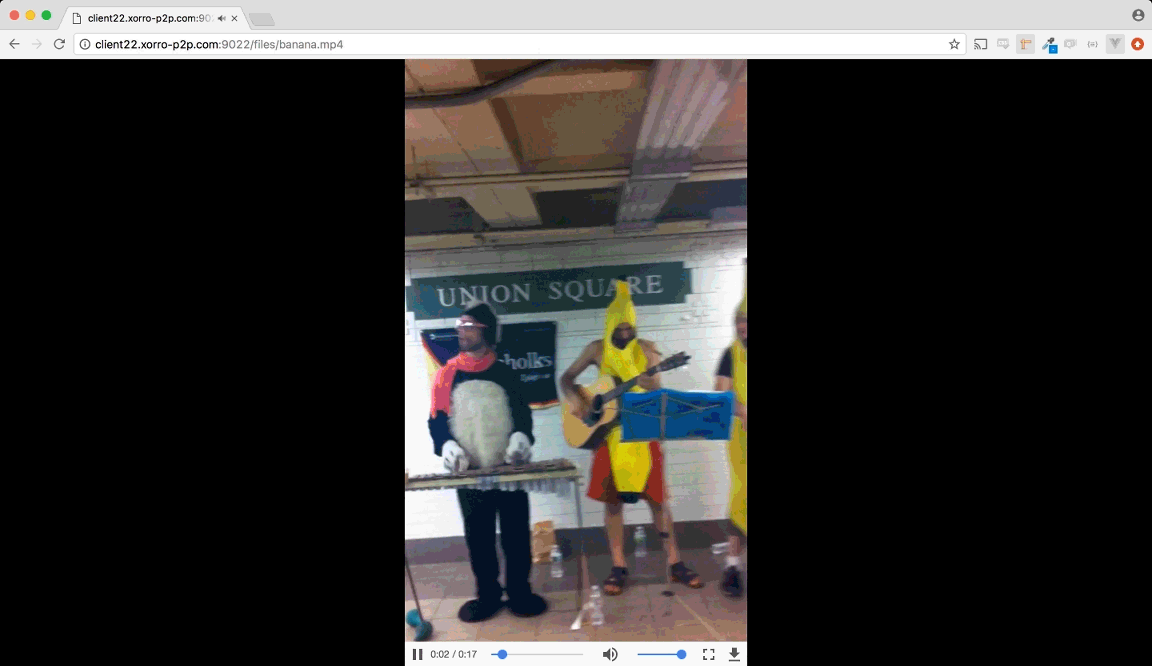
因為Xorro P2P是一個檔案分享的系統, 本身所有擁有的檔案在分散式雜湊表中都會以key/value保存, key為file id, value是檔案位置.
Kademlia通訊協定
Kademlia網路中的節點有四種基本指令(primitive operations)用來傳送和接收指令.
PING
就像網路控制消息協定(Internet Control Message Protocol, ICMP)中的Ping, 用來確認其它節點是否仍存活在網路中.
FIND NODE
由查詢特定節點ID開始, 接收者查看自己本身的路由表後, 回傳數個和特定ID最為相近的節點.
FIND VALUE
由查詢特定檔案ID開始, 如果接收者再自身的DHT找到此ID, 將會回傳檔案位置, 反之則和FIND NODE一樣回傳數個和特定ID最為相近的節點.
STORE
把自身所擁有檔案的key/value pair儲存在接收者的DHT segment中.
每一個成功的RPC, 傳送者和接收者都會把對方的聯絡資訊加入自己的路由表中.
尋找網路中的節點和檔案
使用者如何在Kademlia網路中找到其他節點或檔案呢?我們以現實生活中的例子來舉例.
如果你想要找到你現實生活中不認識的人, 比如他的名字叫小柯, 你大概會採取以下幾個步驟::
- 詢問你朋友中可能認識小柯的人, 詢問朋友的可能人選和小柯在同一個工作領域或是住在同一座城市.
- 如果其中有一個朋友知道小柯, 那這朋友提供給你小柯的聯絡資訊, 查詢到此結束.
- 如果你詢問的這些朋友都不知道小柯, 他們提供所知道的朋友中, 可能認識小柯的朋友資訊給你.
- 然後你再詢問這些人, 看他們認不認識小柯 上述這些步驟會一直持續到小柯被你找到了, 或是某些停止找尋的條件成立了(例如你最多只聯絡八個人).
Kademlia的節點在查找節點或檔案時, 所依循的模式就和你找人的模式相同.
如果你想要從網路中找尋一個檔案, 你從你自身的路由表中選擇幾個和目標檔案id較相近的節點, 並對這些結點送出FIND_VALUE RPC. 如果任何一個接收者在自己的DHT segment找到了目標檔案, 它將回傳此檔案的位置給你, 否則它回傳更接近此檔案的幾個節點給你. 你就可以再對這些更接近的節點們進行檔案的找尋.
在現實生活中的人與人之間距離可以很簡單的有不同種定義, 例如工作性質, 居住城市或是共同的興趣等 那麼問題就來了, 所謂'距離'在Kademlia的網路中到底是怎麼決定的呢?
距離的計算
Kademlia 定義節點間距離的方式是對兩節點的ID進行位元互斥或運轉(exclusiveo or, xor). xor運算比較兩個輸入值: 如果輸入值一樣, 結果為false(0); 如果輸入值不同, 結果為true(1). 在Kademlia中, 我們會將兩者id轉換為二位元並進行xor運算來定義兩節點之間的距離.
作為範例, 下圖中定義一個網路中位元空間長度為4, 以節點ID為11為基準, 計算節點和其他節點間的結果來展示距離的概念.
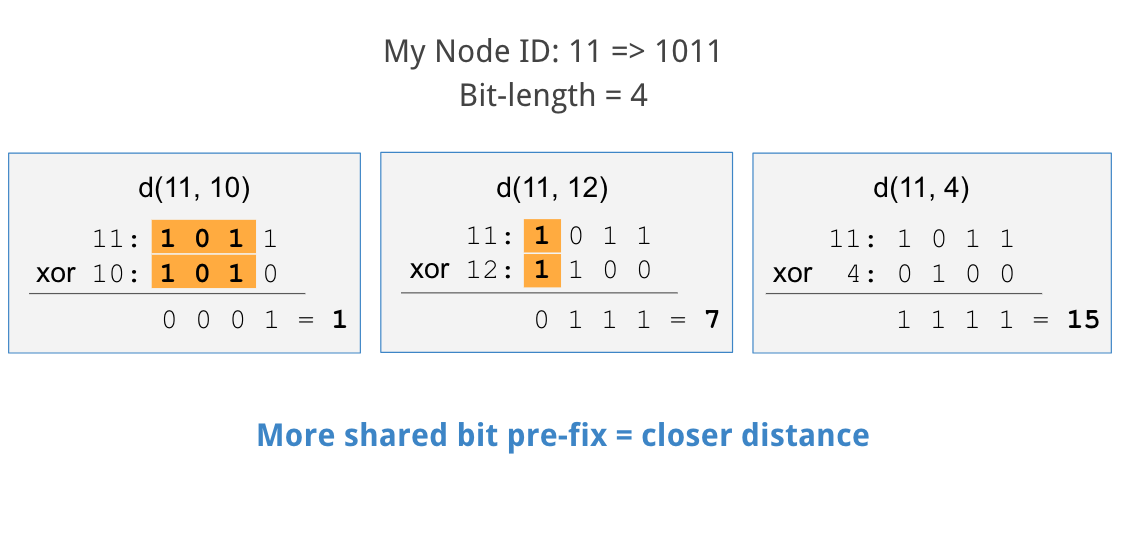
第一個例子, 計算我們節點ID11和節點ID10的xor運算結果. 此兩者ID的前三個位元相同, 只有最後一個位元不同, xor計算結果在二位元中為0001, 十進位為1.
再來計算節點ID11和節點ID12進行xor運算結果. 只有第一個位元相同, 其他位元皆不同, 在二位元的結果為0111, 十進位為7.
最後一個例子為節點ID11和節點ID4之間的xor運算. 此兩者id完全不同, 在二位元的xor運算結果為1111, 十進位為15.
從這三個例子你會發現xor運算一個現象為, 如果兩ID以二位元表示時所共有的位元相同個數越多(從左開始計算), xor運算的結果值越小. 若套用到以xor運算來計算兩節點間距離的Kademlia, 如果兩者間的ID以二位元表示時相同的位元個數越多, 兩節點的距離越接近
Kademlia網路和路由表
在Kademlia網路中的每個節點都可以被看為一個二叉樹的樹葉. 在下圖我們畫出所有在位元空間長度為4的可能的節點id: 0-15, 從root出發, 每一步往左則在位元組新增一個0, 往右則在位元組新增一個1.
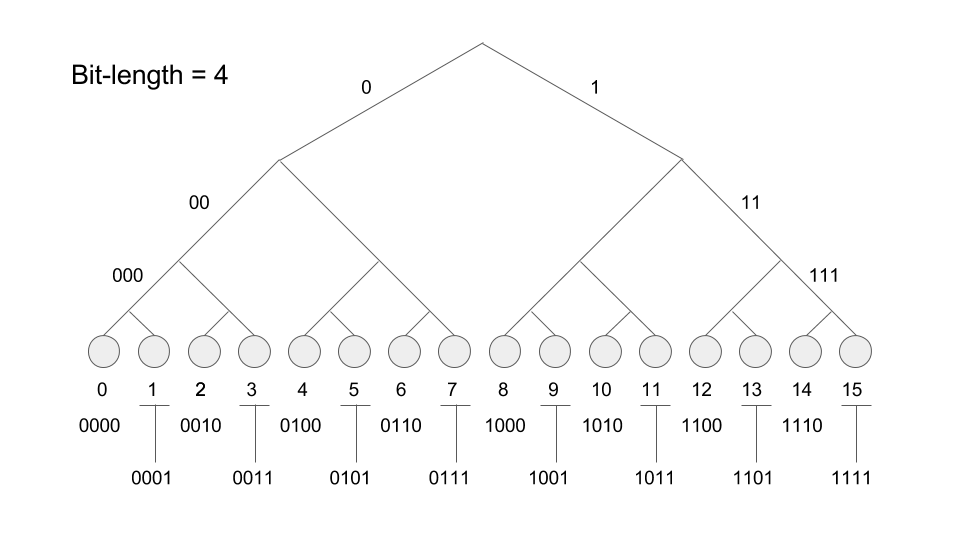
一個有效的二叉樹最重要的特色就是, 找尋其中一個樹葉的時間複雜度為O(log n); 在Kademlia網路中我們想尋找一個節點的過程就和在二叉樹中找一個樹葉一樣, 尋找的過程將會是非常有效率的.
在先前有提到, 一個路由表內將會分類為許多K桶, 每一個K桶都包含了許多與自身相距特定距離的聯絡資訊. 此相距特定距離即是我們先前所提到的位元相同個數, 和當前節點ID擁有一樣的位元相同個數的節點們將會被分類在同一個K桶中
從下圖可以更清楚的看到, 同樣在位元長度為4的網路下我們的ID為11, 和我們ID11有3個相同位元個數的10將會被分類在第一個K桶中, 2個位元相同個數的8和9將會被分類在另一個K桶中, 1個相同位元個數的12, 13, 14和15在第三個K桶中, 其餘在被分類在同一個K桶中.
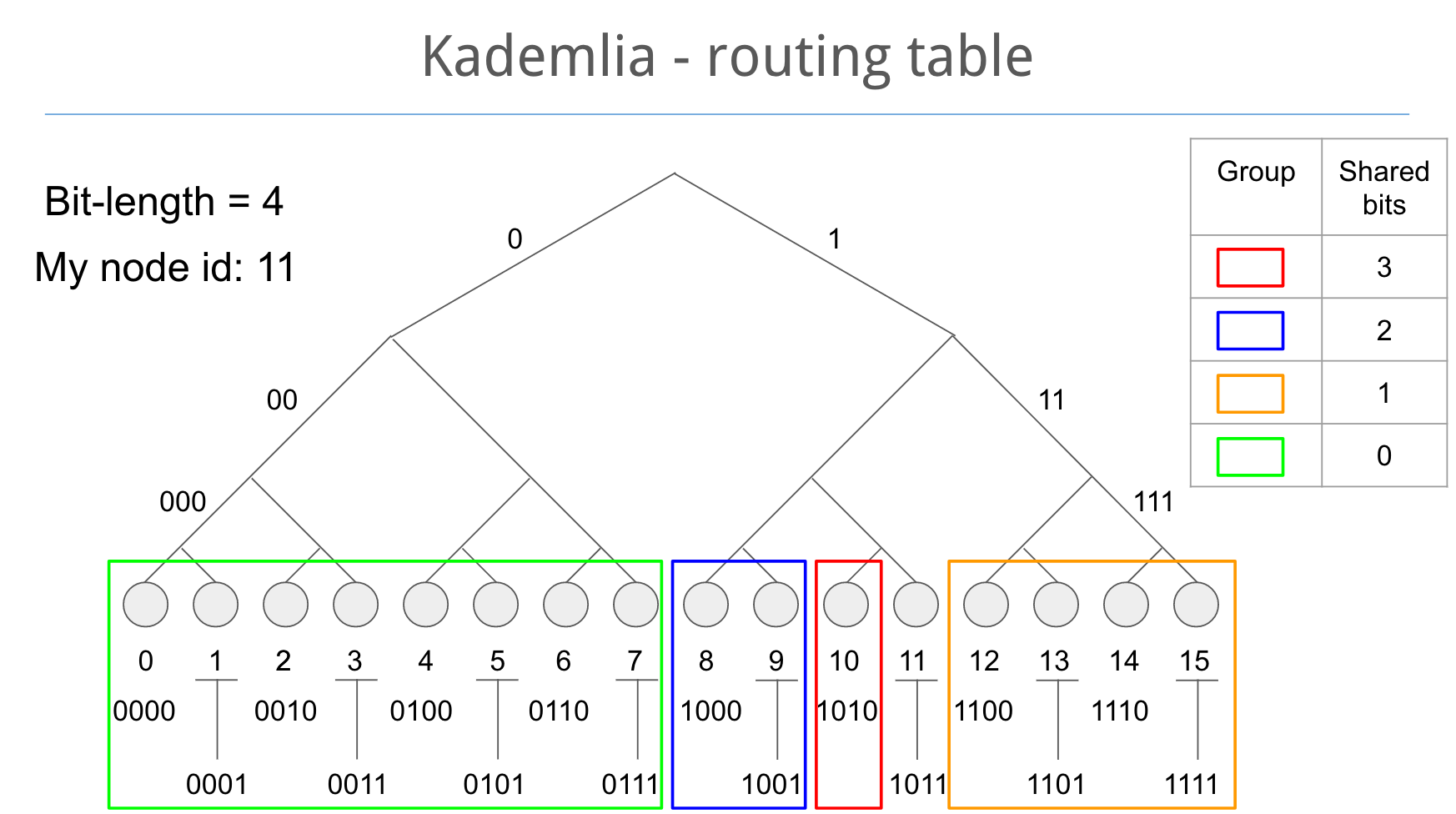
這樣的分類就和你把你的朋友依照特定的方式分成不同的群組一樣(如: 就讀的學校, 工作的性質等), 一個節點可以很有效的對一個特定群組內的數個節點同時相同的RPC呼叫(FIND_NODE, FIND_VALUE, STORE), 讓節點可以很有效的查詢節點, 檔案或是散佈我們所擁有的檔案
檔案分割與重組
檔案分割是把一個檔案切割為較小片段, 命名每個片段, 最後把原檔名以及分割片段的名稱放入種子檔的步驟, 因此他們可以透過種子檔案而被外界取得.
在前面介紹的頁面有提到, 檔案分割是Bittorrent的一項重要特色, 此專案中也會實作此功能.
檔案分割可以提升檔案在網路中的分散度和可靠度, 原因為: 複數使用者在本機中存儲同個分割檔, 當節點下載檔案時, 即時某些存有此分割檔的節點下線, 我們仍然可以從其他來源下載分割檔.
這項特色也可以在大型檔案分享時藉由分散不同分割檔到不同節點上, 節省我們上傳的頻寬
在實作上我們以清單(即BT中的種子, 後面即稱為種子)來記錄檔案分割的資訊, 並以此清單來合併分割檔
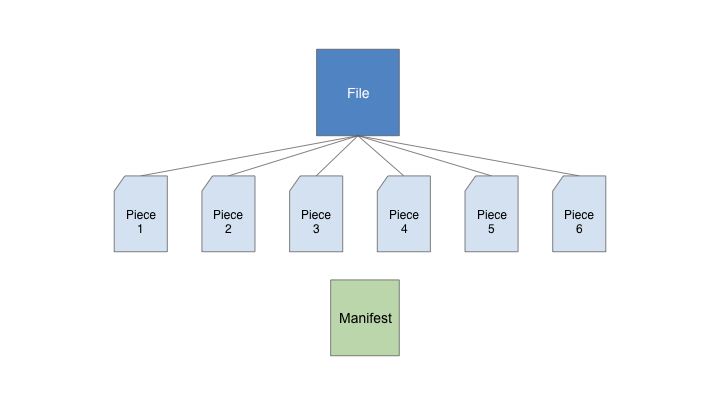
在我們的專案中, 檔案分割的實作步驟如下:
- 透過drag & drop功能來上傳檔案.
- 上傳檔案後, 對此檔案內容做雜湊運算來取得ID
- ID也同時是種子的檔案名, 副檔名為".xro", 此步驟在背景自己產生, 使用者只會知道最後產生的ID
- 原始檔案被以片段大小1MB來進行檔案分割, 若小於1MB則以50%遞減大小來進行分割
- 分割檔會被寫入磁碟中, 每個分割檔的檔名是由其內容的雜湊運算產生
- 原檔名, 檔案大小(以bytes表示)和分割檔名依序寫入種子檔中
- 種子和分割檔會透過STORE RPC散佈給與檔案ID相鄰節點們. 相鄰節點會接收到檔案ID和檔案位置
下圖種子檔案以JSON格式顯示:
{
"file_name":"banana.mp4",
"length":9137395,
"pieces":[
"272610812651008498817059664145444816819140431736",
"255845820650928817902394043384061703021184974492",
"709124865584808529999187320247131501825035282844",
"463972141944555281071361859762050722622562309482",
"665233928362169136349271011451642022996948352498",
"460767108478119568061824765684889409150273585314",
"242856439500459087965632547950882773486858003109",
"1113118586291233368092664992853829437069513635744",
"55094692080869844054492088107211106202780121432"
]
}
開發策略: 模擬和擴展一個網路application從本地環境到真正網路
Phase 1: 測試模式
在專案的早期階段, 我們需要測試節點間的溝通, 但此時我們還沒有真正的網路和RPC傳輸以及很多台電腦, 所擁有的只有物件的類別(class)和測試套件.
一開始最直覺的測試方式為在REPL(irb)上創造許多節點物件, 再手動輸入指令讓他們交流. 當然上述步驟可以創建腳本執行, 可是一但我們真正在網路環境上進行交流, 或是節點物件不在同一台電腦上執行時, 此腳本將無法繼續使用.
因此我們需要代理物件分別在本機模式和網路環境時會有不同的行為模式以利我們進行測試
我們的解決方法為讓所有節點間的通訊交由給已經存在的Network Adpater物件.
在測試時, 代理物件即Fake Network Adapter —所有節點都會儲存在array中以供查詢. 讓我們可以在本機環境測試節點間交流的RPC傳輸協定, 流程如下圖所示.
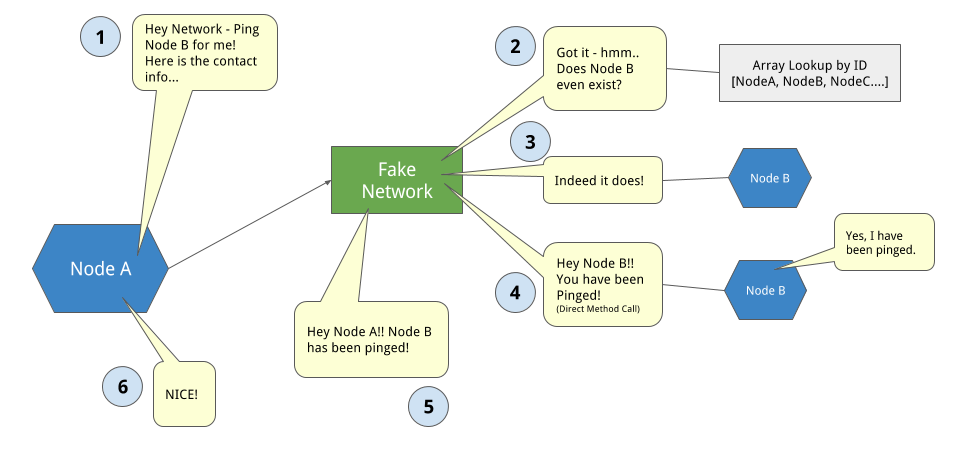
- 節點A透過網路傳遞RPC給節點B, 節點A提供聯絡資訊包括ID, IP和port.
- 網路尋找節點B, 如果再fake network環境中是以節點ID進行查詢.
- 網路直接對節點B執行遠端程序呼叫, 改變其狀態和/或回傳資料.
- 網路傳遞節點B的回應資料給節點A, 節點A根據資料改變狀態或是對此新資料進行動作.
Phase 2: RPC在本機經由HTTP進行傳遞
下一步就要開始導入HTTP作為RPC物件方法的傳輸協定..
為了完成這項工作, 我們建立了Real Netwrok Adapter物件, 就像先前的Fake Network Adpater類似, 但查找ID是直接經由物件方法的調用來完成. Real Network Adapter對路由表中的聯絡資訊以物件方法調用的方式送出POST request到相對應的路由, 並在request body中包括查詢者的資訊以及查找訊息(節點/檔案id).
工作流程就如同下圖所示:
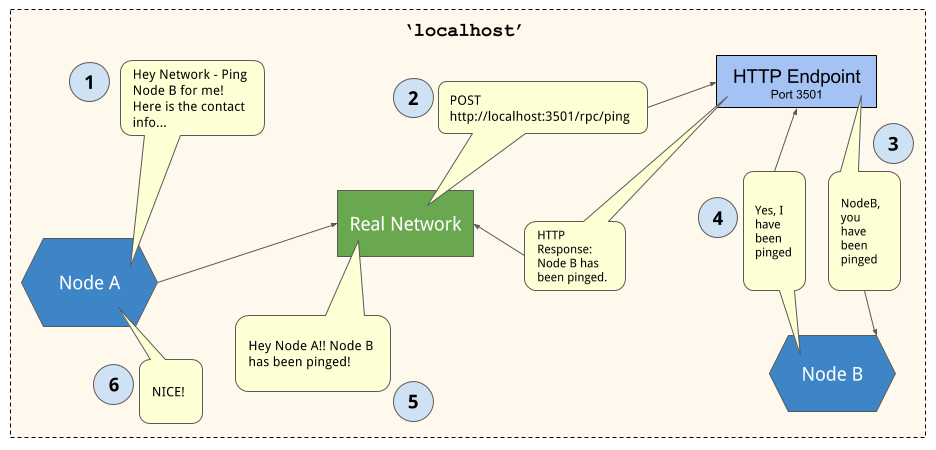
- 節點A經由網路傳遞RPC至節點B, 由節點A提供節點B的ID, IP和port.
- 網路根據上述訊息對節點B傳遞HTTP post requst, 並且在此request上加上附載資料.
- 接收方接收此request, 並根據post request來調用物件方法.
- 回傳訊息被轉為HTTP response並由Real Network Adpater接收.
- 最後由Real Network Adpater回傳給節點A, 節點A根據資料改變狀態或是對此新資料進行動作.
透過把節點間的交流抽象到Network物件和HTTP終端, 節點可以單純的接收和傳遞訊息
Phase 3: RPC/HTTP在網路環境下傳遞
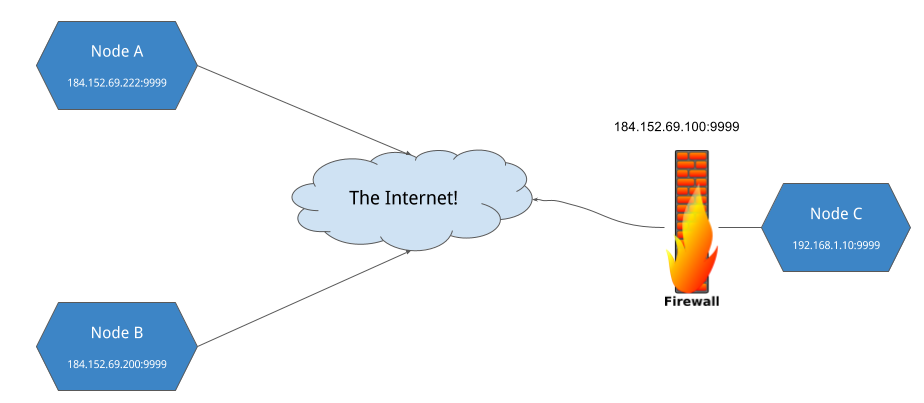
上一個階段我們知道如何在本機上的不同節點之間以HTTP進行交流, 最後一步就是在真正網路上部署我們的節點. 如果系統是在開放的網路環境下, 此交流將會順利的進行, 或是節點雖然位於防火牆後但仍然有開放特定通訊埠.
如果節點是在網路掩蔽(Network Address Translation, NAT)後那就不同了. 他們可以順利地加入並從網路取得資料, 但是如果沒有連接埠轉發(port forwarding), 它將不能接受所有外來的HTTP連接, 因而無法對網路做出貢獻.
以長遠計劃來說, 以TCP/UDP為基礎的RPC和檔案傳輸協議是最終目標, 並且支援STUN和TURN伺服器來處理開放IP/port以及外來的連接. 但是在此專案的實作範疇中, 我們需要一個快速繞過NAT以及Firewalls的方式.
有鑑於此, 我們對第三方軟體穿隧軟體Ngrok進行支援, 在防火牆之後的節點可以健全地參與網路.
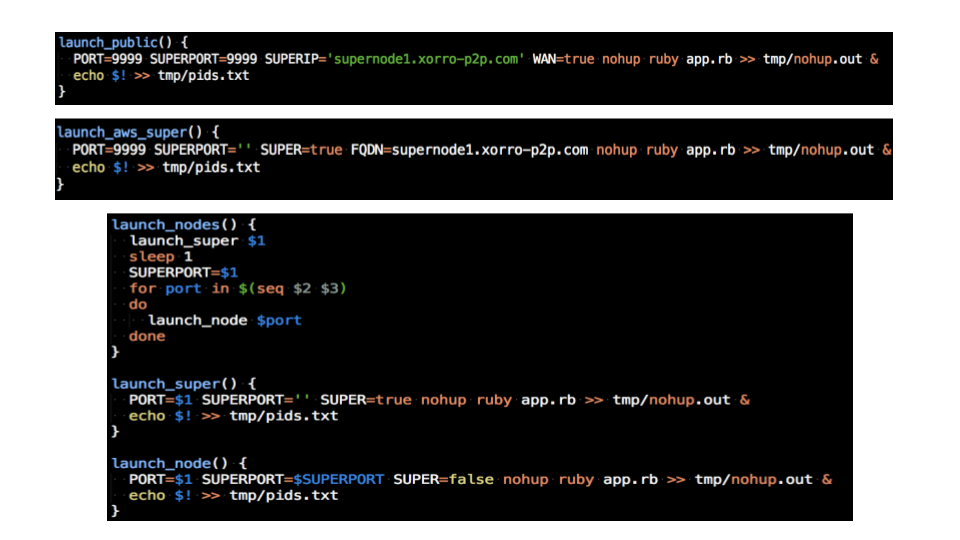
彈性的節點創建和啟動腳本
我們現在必須讓節點在不同的環境下和不同組態中快速切換. 在每個環境中, 節點會廣播自己的IP/port還有每個種子和分割檔的url及路徑
- 只在本機環境下運作, 所有節點只要廣播port即可(都在localhost之下).
- 節點是在直接在網路上運作, 需要的就有public IP和port.
- 節點可以不用廣播ip/port, 如果它有屬於自己的網域.
- 節點在防火牆後但是有設定連接埠轉發(port forwarding), 它仍可直接廣播public IP和port.
- 如果這節點位於防火牆後, 又無法建立通道來接收HTTP request時它可以:
- 透過Ngrok伺服器來創建通道, 此節點會知道自己Ngrok位址來和其他節點交流.
- 那這節點對這網路來說是一個寄生節點.
從上述這些節點可能的狀態和所具有的環境變數, 我們的節點BASH啟動腳本據此條件彈性的啟動, 模式有下列四種: test, local, lan, WAN
系統架構
最後我們的系統架構如下圖:
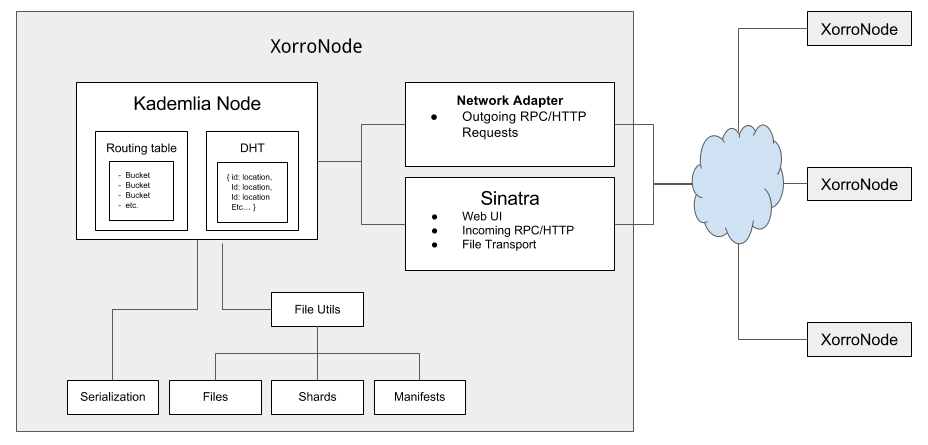
最高層的物件為XorroNode, 這是一個模組化的Sinatra application
每一個XorroNode包含:
- 一個Kademlia節點, 負責保管路由表和DHT segment
- Network Adpater來發起RPC給其他節點.
- Sinatra endpoint來接收從其他節點發出的RPC, web UI和檔案傳送.
- File Utilities對檔案進行切割, 合併以及種子的創建.
未來展望
初版的Xorro P2P已經可以像P2P軟體運作, 但是仍有幾處需要改進的地方, 條列如下:以TCP/UDP為基礎的RPC和檔案傳輸取代HTTP
現有版本使用HTTP作為傳輸協定的原因為, 利用HTTP已有的工具使我們可以專注在開發DHT上. 但是若以TCP/UDP為基礎來做檔案傳輸可以有效的避免我們所遇到的防火牆以及NAT問題.
不用web UI來上傳檔案
儘管我們非常用心設計我們的web UI, 但是現有的檔案上傳方式是經由瀏覽器整合Javascript FileReader api所構成, 在檔案大小上有所限制, 因為我們是經由POST request傳輸, 檔案內容為request body. 以HTTP伺服器接受重組檔案, 再進行分割
計劃為重新建構這個工作流程, 在資料夾中可以加入手動加入檔案, 自己偵測檔案加入後開始進行分割/分享. 更長遠的考量為建構一個cli介面來完成這項工作.
結語
希望你喜歡我們開發Xorro-P2P的故事
若有任何問題, 歡迎聯絡我們!
 Ken Chen
Ken Chen David Kurutz
David Kurutz Terry Lee
Terry Lee