Xorro P2P is a BitTorrent-like peer-to-peer file sharing network built by software engineers Ken Chen, David Kurutz, and Terry Lee.
Interested in P2P networks and distributed systems, we set out to build our own from scratch. The version available today is our alpha release, providing a working proof-of-concept. We want to continue improving upon Xorro — upcoming features are listed further down this page.
This site outlines our journey building Xorro P2P. We hope that readers leave with a better understanding of the P2P problem space.
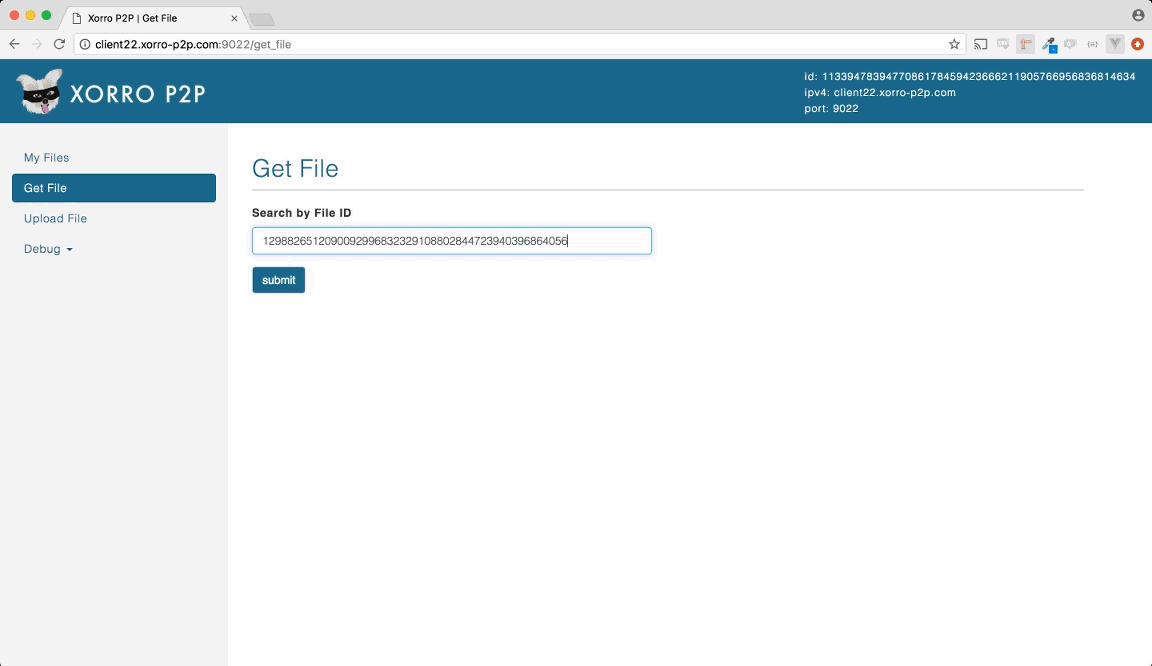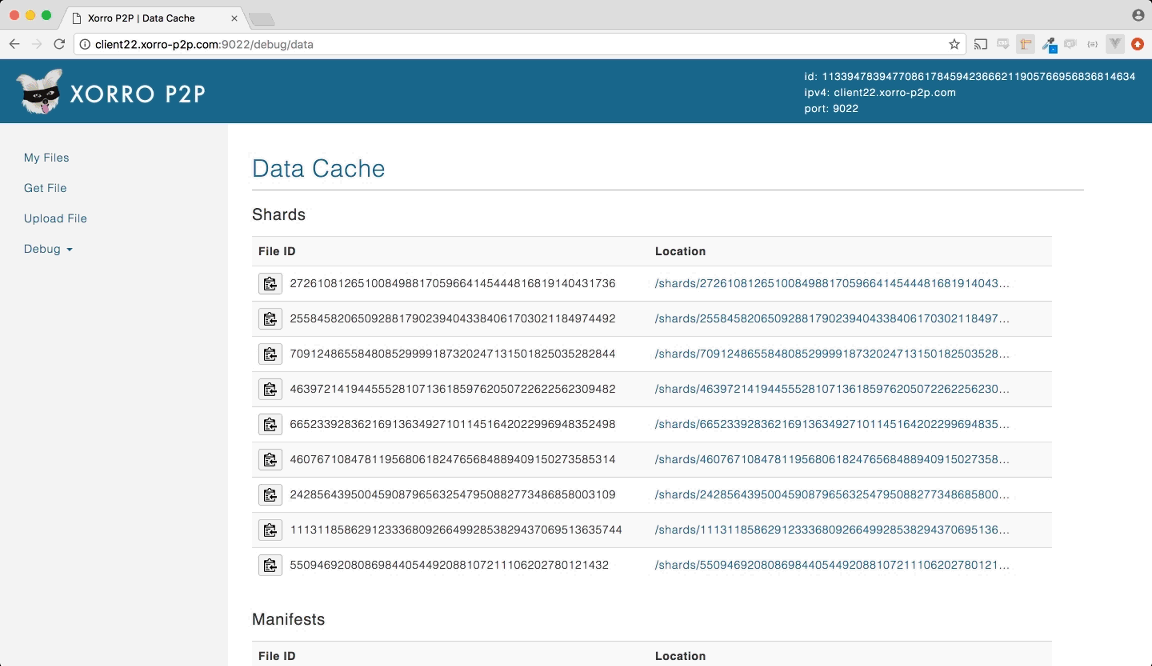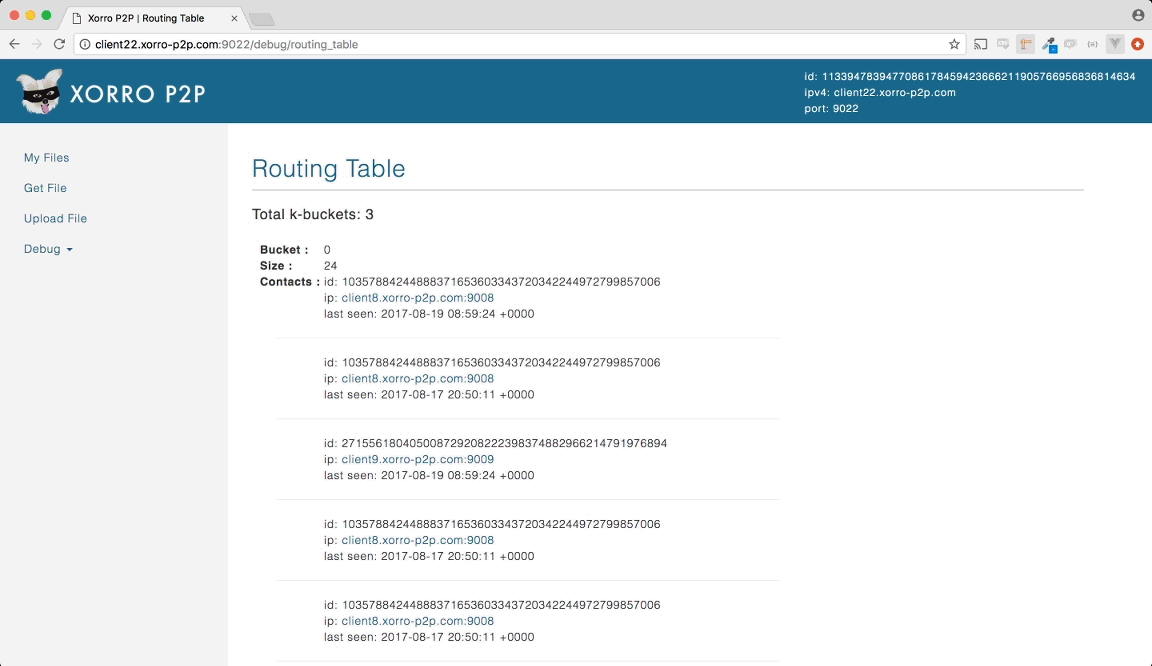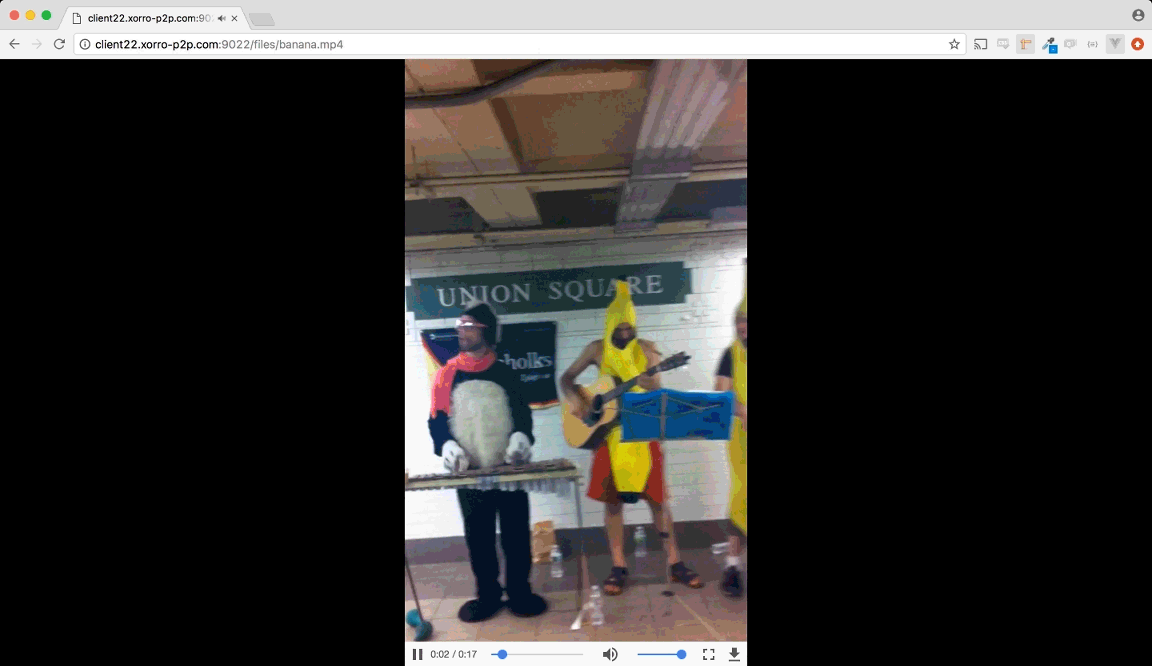
Table of Contents
- Research Phase
- Selecting Features
- Demo
- Implementing a Distributed Hash Table
- File Sharding and Retrieval
- Development Strategy
- System Architecture
- Future Work
Research
As strictly end users of P2P systems, we started our journey facing a very large learning curve. Much research was needed for us to understand the history and internals of these systems. We collectively read up on P2P networks, old and new: Napster, Gnutella, Freenet, BitTorrent, IPFS...
Centralized vs Decentralized
An important concept to understand is the difference between centralized and decentralized systems. A comparison of first and second generation networks helps to illustrate the difference.
Napster: Centralized
Napster was a P2P file sharing service that was mostly used to transfer music files, and was popular from 1999-2001, It’s estimated that there were about 80 million registered users at its peak. Napster worked by having all nodes connect to a central index server that contained all the information about who was in possession of which files.
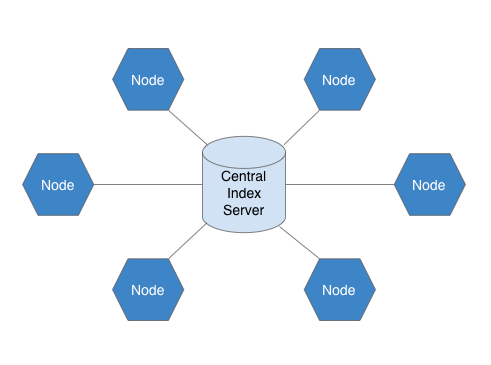
Due to its centralized nature, Napster was vulnerable to attacks and lawsuits and Napster was shut down by court order after about 2 years of service. In addition to those vulnerabilities, the central index meant there was a single point of failure, as well as a lack of scalability.
BitTorrent, Gnutella, Freenet: Decentralized
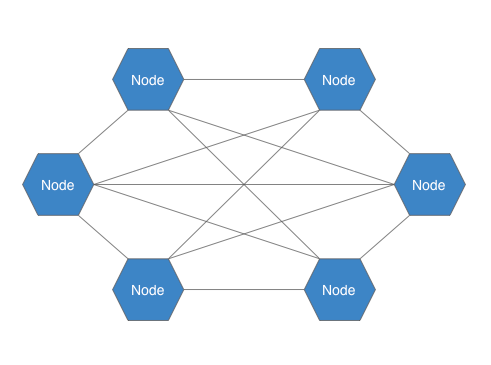
The next generation of P2P networks were able to escape the same fate as Napster by moving to a distributed model.
In a decentralized system like BitTorrent, every computer/node acts as a client and server, maintaining its own segment of a file lookup index. Nodes can find out about the locations of files through other nodes, removing the reliance on a central server.
Focusing on P2P File Sharing Systems
Knowing the advantages of newer P2P systems, we went down the path of investigating their features more deeply. Luckily P2P networks have been around for a while so there were many resources available. White papers about distributed hash tables (DHTs) proved to be the most critical, as DHTs are the foundation of current P2P networks. Countless hours were spent reading and digesting white papers, specification documents, blog posts, and StackOverflow answers. We made sure to have a good understanding of DHTs before we started any coding.
A list of resources we found helpful is located here.
Selecting Features
BitTorrent Key Features
After comparing P2P networks, we ultimately zeroed in on a set of features found in BitTorrent as the model for the first version of our application. Each of these features will be described in detail further on.
- Distributed Hash Table
- File Sharding
- Nodes that act as both clients and servers
Demo
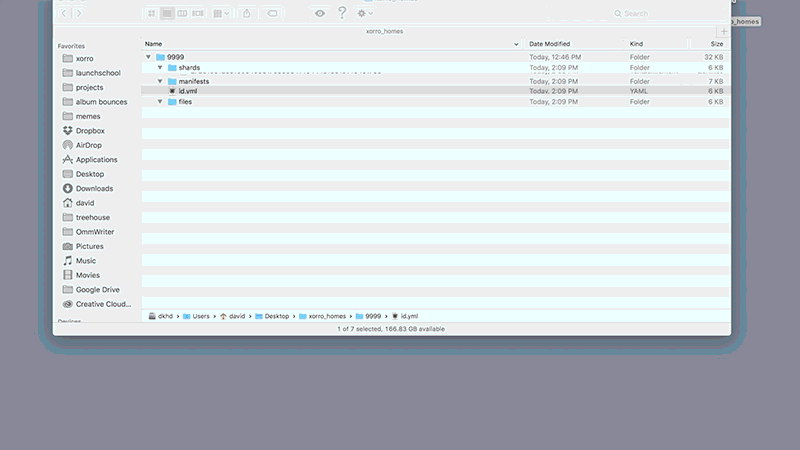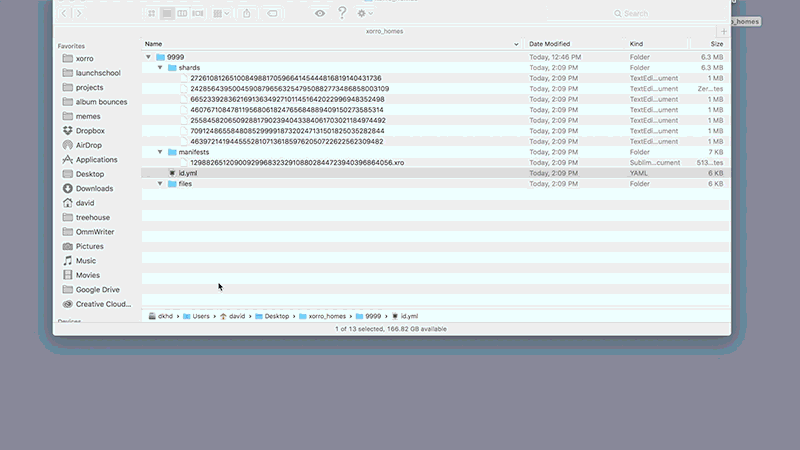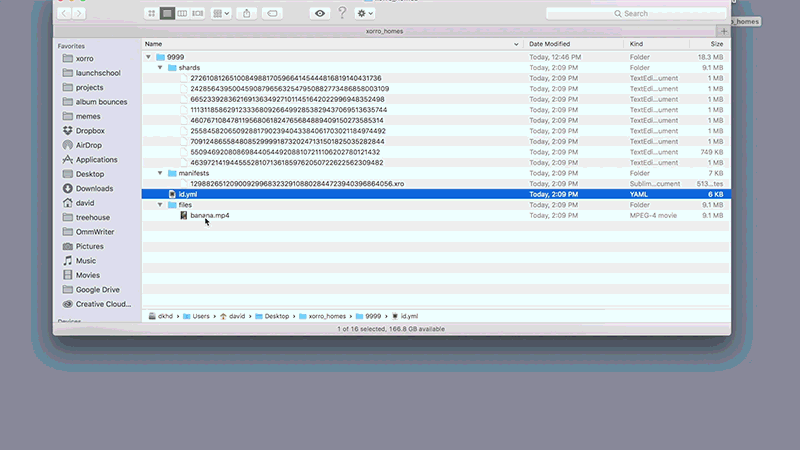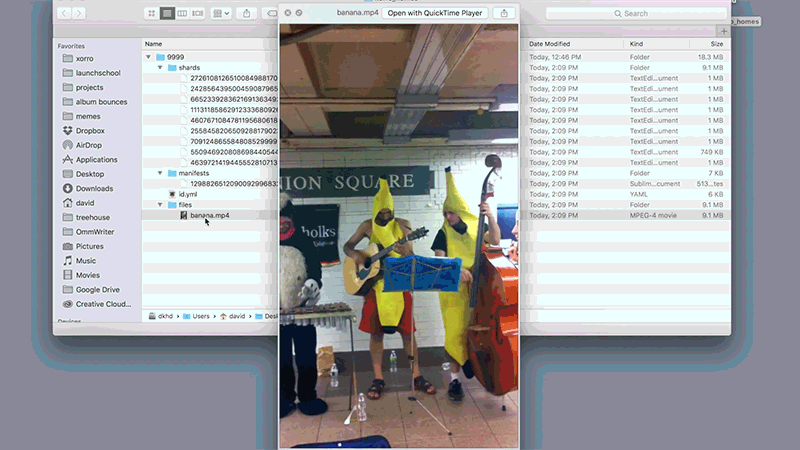
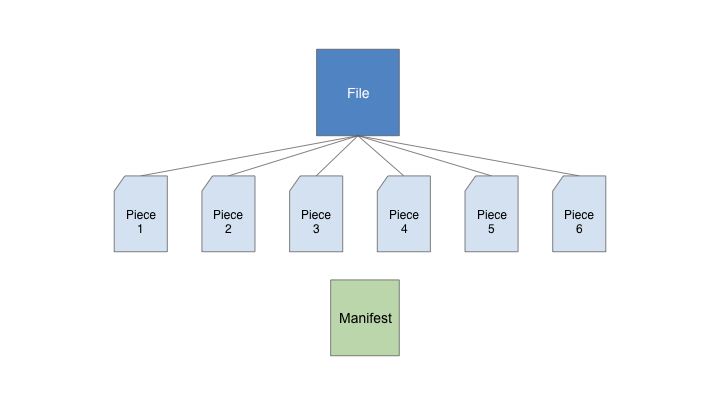
Before we get into the implementation details of Xorro P2P, check out this graphic that illustrates the file downloading process in action.
First, the manifest file is downloaded, followed by each shard listed in the manifest. Once all shards are downloaded, they are reassembled back into the original file.
Implementing a Distributed Hash Table
Our research uncovered several distributed hash table models to consider for our application: Chord, Pastry, Apache Cassandra, Kademlia... each with their own pros and cons. We ultimately decided on Kademlia due to its prevalence, minimal remote procedure calls, and automatic spreading of contact information, among other reasons we will outline shortly.
Implementation of Kademlia proved to be quite challenging due to the large quantity of new concepts: nodes, routing tables, buckets, xor distance, routing algorithms, remote procedure calls… the list seemed endless. There were a few Ruby implementations out there, but we relied only on specifications and white papers because we truly wanted to build out the DHT from scratch.
Kademlia
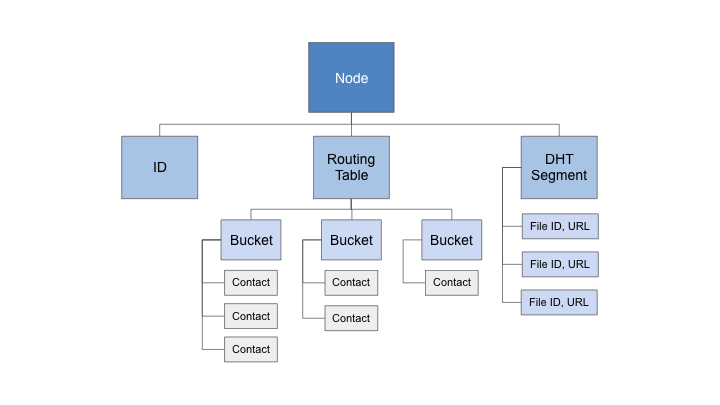
A Kademlia network consists of many Nodes.
Each node:
- Has a unique 160 bit ID.
- Maintains a routing table containing contact information for other nodes.
- Maintains its own segment of the larger distributed hash table.
- Communicates with other nodes via 4 remote procedure calls.
Each node's routing table is divided into 'buckets' — each bucket contains contact information for nodes of a specific 'distance' from the current node. We will discuss the concept of distance in more detail shortly.
Each contact contains the ID, IP address, and port number of the other node.
Because Xorro is a file sharing application, the DHT segment will contain key/value pairs where each key is a file id, and the corresponding value is the file location.
Node Communications
There are four primitive remote procedure calls that Kademlia nodes send and respond to.
PING
Much like an Internet Control Message Protocol (ICMP) Ping, this is used to verify that another node is still alive.
FIND NODE
This RPC is sent with a specific node ID to be found. The recipient of this RPC looks in its own routing table and returns a set of contacts that are closest to the ID that is being looked up.
FIND VALUE
This RPC is sent with a specific file ID to be located. If the receiving node finds this ID in its own DHT segment, it will return the corresponding value (URL). If not, the recipient node returns a list of contacts that are closest to the file ID.
STORE
This RPC is used to store a key/value pair (file_id/location) in the DHT segment of the recipient node.
Upon each successful RPC, both the sending and receiving node insert or update each other’s contact info in their own routing tables.
Finding Peers and Files
How does a node find other nodes or files in a Kademlia network? We can compare this to a real life example.
If a person wants to find another person they don't know, they might take the following steps:
- They could ask their friends who are closer to the target person. Perhaps these friends work in the same industry or live in the same city as the target.
- If one of these friends knows the target, that friend can provide the target's contact info, and the lookup is complete.
- If these friends don't know the target, they could each instead provide contact information for other people who are even closer to the target.
- This new set of contacts can then be queried, and the process is repeated until the target is found, or until some failure condition is reached.
Kademlia nodes follow a similar pattern when conducting lookups.
If a node is to retrieve a piece of information (a file) from the network, it will send FIND VALUE RPCs to a subset of its own contacts whose IDs are 'closest' to the ID of the file it is looking for. If any of the recipient nodes have this ID in their DHT segment, they will return the corresponding value, otherwise, they will return a list of contacts that are even closer to the value being queried.
The next problem to discuss is how 'closeness' is determined in a Kademlia network.
Calculating Closeness
Kademlia defines the distance between nodes as the bitwise exclusive or (XOR) of the nodes' IDs. The xor operation compares two inputs: if these inputs are the same, the result is false (0), if the inputs are different, the result is true (1). The XOR of two numbers is calculated by finding the XOR of each bit in the binary representation of those two numbers.
As an example, the diagram below assumes a node ID of 11 in a 4 bit keyspace (only IDs of 0-15 are possible). We calculate the XOR of 11 with a few other IDs to demonstrate the concept.
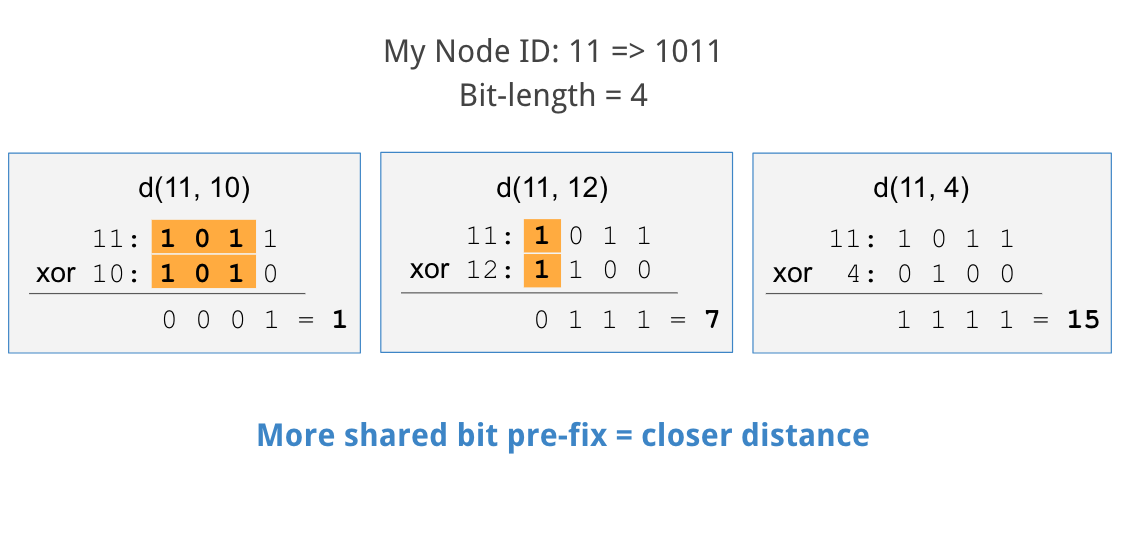
In the first case, we calculate 11 XOR 10. The first three bits in both IDs are the same, and only the last bit is different. The result of 11 XOR 10 is 0001 in binary, or 1 in decimal.
Next we calculate 11 XOR 12. Here, only the first bit is the same while all others are different. The result of 11 XOR 12 is 0111 in binary, or 7 in decimal.
Our last example calculates 11 XOR 4. Here all bits are different, resulting in 1111 in binary, 15 in decimal.
From these results you'll notice an important feature of a Kademlia's XOR metric: if the binary representation of a node’s ID shares a larger common pre-fix with the current node, the resulting XOR is smaller.
Kademlia network and routing table
Each node in Kademlia can be thought of as a leaf in a binary tree. Below we map out all possible IDs in a 4 bit keyspace: 0-15, where each left child adds a '0' at the bit corresponding to that child's depth and each right child adds a '1'.
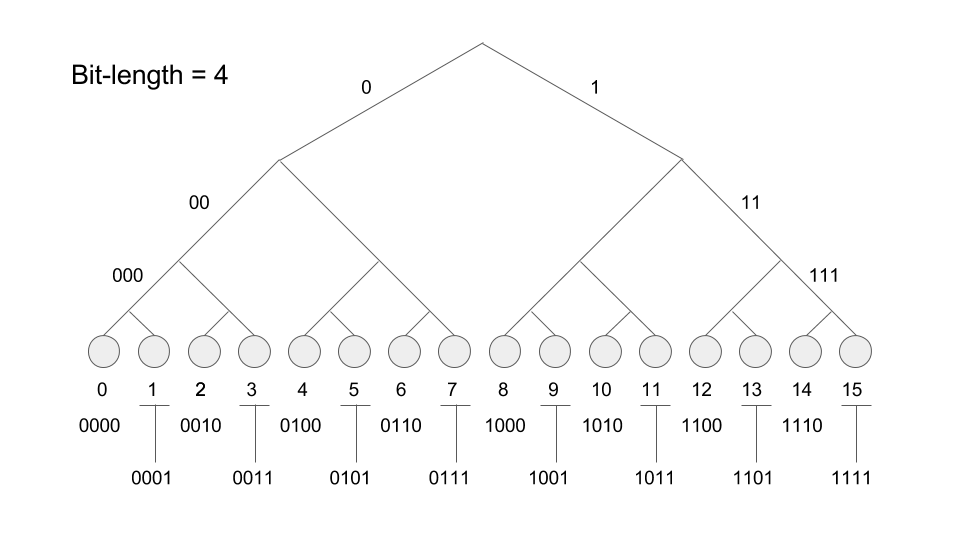
The most important feature of a binary tree related to a Kademlia network is the O(log n) lookup time. Looking up a node or file in this network is a very efficient procedure.
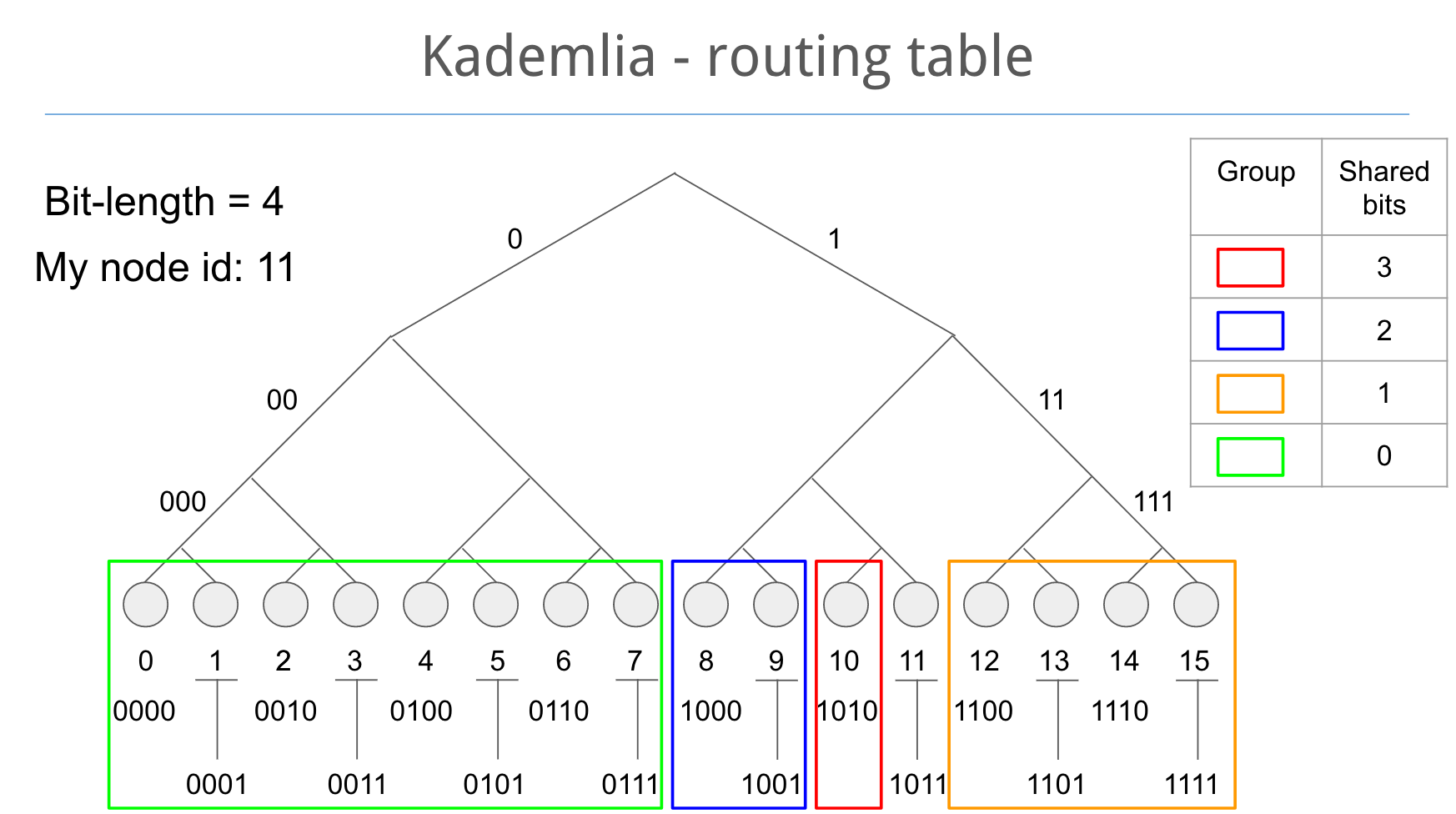
As mentioned earlier — a routing table groups contacts into buckets with each bucket containing contacts of a certain distance. That distance is the 'shared bit length', which is obtained by calculating the XOR of the contact's ID with the current node's ID.
Below we see how those buckets would be organized in a node whose ID is 11 in a 4 bit keyspace. Nodes whose IDs share a 3 bit prefix with the current node go in one bucket, 2 shared bits in a different bucket, etc.
File Sharding and Retrieval
File sharding is the process of chopping up a file into smaller pieces, naming the pieces, and documenting the files/names in a manifest file such that they can be retrieved and reassembled in the appropriate order.
Sharding improves distribution and reliability of a P2P network, as multiple nodes can store some or all shards of a shared file. If a node containing download information for a shard goes offline, the shard info can be retrieved from a different source.
File sharding also saves bandwidth, where the load of sharing potentially large files is distributed amongst many nodes.
In our implementation, the file adding and sharding process looks like this:
- A shared file is added to the network via drag & drop.
- An ID is created for the file by calculating the SHA1 hash of the file's content.
- This ID is repurposed as the filename for the manifest file, with a ".xro" extension. This process is transparent to the user, who only needs to be aware of the ID.
- The original file is sharded into either 1MB chunks, or 50% of the original file size if it is smaller than 1MB.
- Each shard is written to disk - the name of the shard is the SHA1 hash of its content.
- The shards names are written in order to the manifest file, along with the original file name and file size in bytes.
- Manifest and shard location information is broadcasted to peer nodes with the STORE RPC. For each shard/manifest, the hosting node looks in its own routing table for the closest nodes to the ID of the file. Each of these peer nodes receive a STORE RPC containing the ID and location of the file
Below we have the contents of a manifest in JSON format:
{
"file_name":"banana.mp4",
"length":9137395,
"pieces":[
"272610812651008498817059664145444816819140431736",
"255845820650928817902394043384061703021184974492",
"709124865584808529999187320247131501825035282844",
"463972141944555281071361859762050722622562309482",
"665233928362169136349271011451642022996948352498",
"460767108478119568061824765684889409150273585314",
"242856439500459087965632547950882773486858003109",
"1113118586291233368092664992853829437069513635744",
"55094692080869844054492088107211106202780121432"
]
}
File retrieval is handled similarly:
- A user enters the ID of the file they want to retrieve from the network. This ID is the hash of the file's content, and also happens to be the name of the manifest file they retrieve first.
- The manifest file is retrieved from the network by issuing FIND VALUE RPCs to peer nodes closest to the ID of the manifest.
- Once the manifest is downloaded, the node repeats the lookup and download process (FIND VALUE RPC) for each shard documented in the manifest.
- After all shards have been downloaded, they are reassembled into the original file.
- The node then broadcasts location info for its newly acquired shards and manifest to peer nodes closest to the respective IDs of the files.
Development Strategy: Simulating and Scaling a Network Application From a Local Environment to a Real Network
Phase 1: Test Mode
So.. how did we go about building and testing this?
In the early stages of our project, we needed to test inter-node communications, but all we had were our classes and test suites, there was no network, no RPC transport, not even multiple computers.
It was fairly common for us to fire up Ruby's interactive shell (IRB), instantiate a few nodes, and get them communicating manually. Of course this could be scripted, but it breaks down quickly once a true network environment is introduced and node objects aren't directly available in the same Ruby process.
We needed some sort of proxy object that would function one way during testing and local development, and another way when deployed in a real network environment.
Our solution was to have each node delegate all network communications to a pre-existing Network Adapter object.
When testing, this Network Adapter would actually be a ‘Fake Network Adapter’ — essentially an array of other nodes, with some methods for lookup and RPC proxy. This allowed us to test our node interactions in a local sandbox without an RPC transport protocol.
The typical workflow would look something like the diagram below.
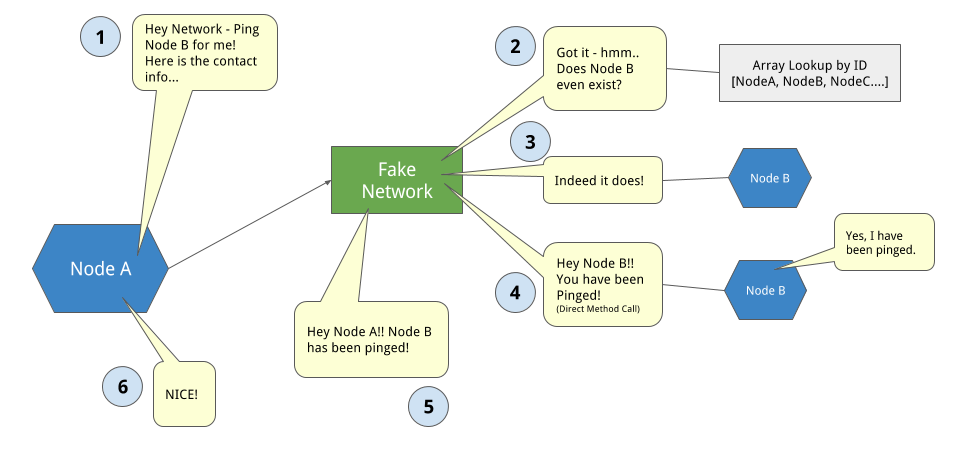
- Node A asks the network to deliver an RPC to Node B, Node A provides the contact info - ID, IP and Port.
- Network looks up if Node B exists — in Fake Network environment this is done by ID from contact.
- Network directly calls method on Node B, which changes state and/or returns some data in response.
- Network delivers that response back to Node A, which in turn changes state or reacts to this new information.
Phase 2: RPC via HTTP in a Local Sandbox
Our next step was to introduce HTTP as the underlying protocol upon which we built our RPC methods.
To do this, we implemented a Real Network Adapter object. It has the same interface as our Fake Network Adapter, but instead of looking up the recipient node by ID and calling the method directly, the Real Network Adapter crafts an HTTP Post request from the IP/Port listed in the contact info provided and the route corresponding to the RPC call, possibly including relevant data in the request body — contact info of the requester, query info, etc.
The typical workflow is similar to the previous slide:
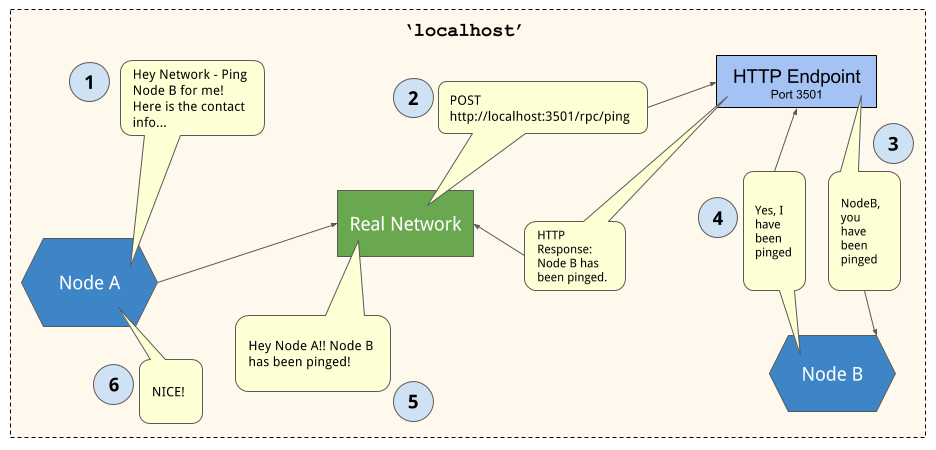
- Node A asks the network to deliver an RPC to Node B, Node A provides the contact info - ID, IP and Port.
- Network crafts an HTTP POST request for the IP, PORT, and RPC path, and sends it along with any payload data.
- HTTP endpoint of recipient node receives POST request, and it calls the receive RPC method on the Node object.
- The return value of this receive RPC method is converted to an HTTP response by the HTTP endpoint, and sent back to the network adapter of the calling Node.
- The Network receives the response, and delivers it to Node A, which in turn changes state or reacts to this new information.
As you can see, from the perspective of the Nodes, nothing has changed — each of them send and receive the same information, but the Network Object and HTTP endpoints abstract away the internode communications.
Phase 3: RPC/HTTP Over the Internet
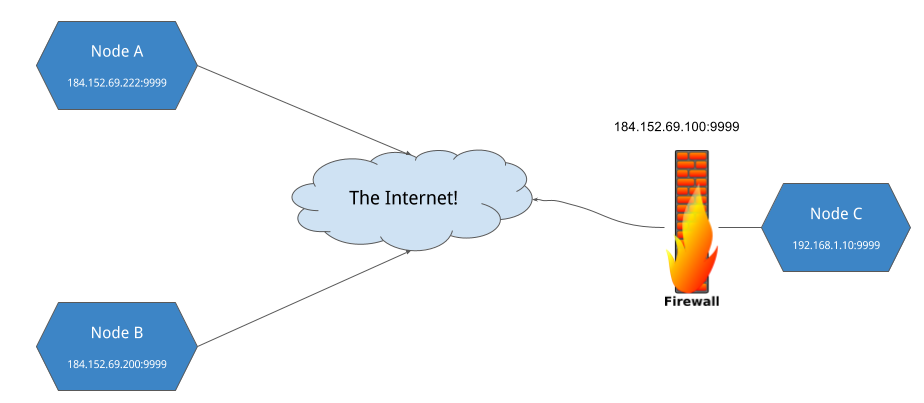
Once we knew that internode communications were working using HTTP, our next step was to deploy nodes onto multiple systems across the internet. This worked fine if the systems were directly on the public internet, or if they were behind firewalls configured with ports already opened up.
Nodes behind a NAT firewall were another story. They could join the network fine and retrieve files fine, but without port forwarding, they cannot accept incoming http connections, and thus cannot contribute to the network.
Long term, a TCP/UDP based RPC and file transport protocol is the goal, as well as support for STUN and TURN servers to handle public IP/port discovery and incoming connections. However, in the scope of this project we needed a quick way to work around NAT and Firewalls.
To do this, we built support for Ngrok, a 3rd party tunneling service, so that nodes behind firewalls could be full functioning members of our network.
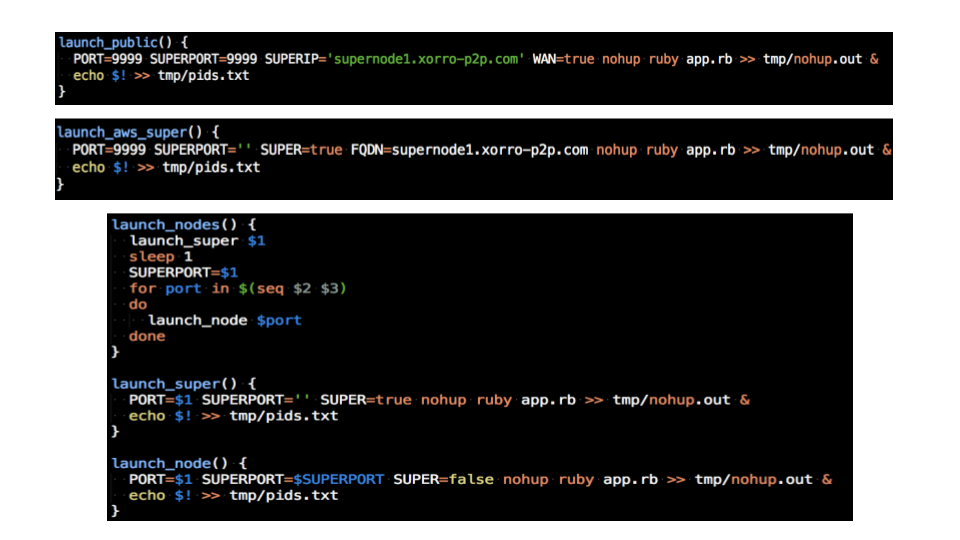
Flexible Node Instantiation and Launch Scripts
We realized that there now was a number of different node configurations/environments that required support and testing. Furthermore we needed a way to move between these configurations quickly and seamlessly
In each environment, a node broadcasts its IP/port, and the full url/path to each shard or manifest it hosts.
- If we are working in a local environment only - all nodes broadcast from 'localhost' at different TCP ports.
- If a node is directly on the internet, it should broadcast its own public IP and port.
- If a node has a fully qualified domain name, the node should broadcast that instead of a numeric IP address.
- If a node is behind a firewall that is configured properly for NAT translation/and port forwarding, it can still rely on its public IP and port.
- If a node is behind a firewall that does not have ports forwarded, it needs to either:
- Establish a tunnel to Ngrok’s servers, and be aware of its unique Ngrok address so it can advertise this to other nodes,
- Know that it is a "Leech" node, and not broadcast location info about any files that it hosts.
We identified a number of configurations that a node might have, and created environment variables to represent these options. Our node instantiation code reacts to these environment variables, and we crafted a series of BASH scripts to standardize these configurations for each environment we were working in: test, local, lan, WAN, etc.
System Architecture
Our final system architecture looks like this:
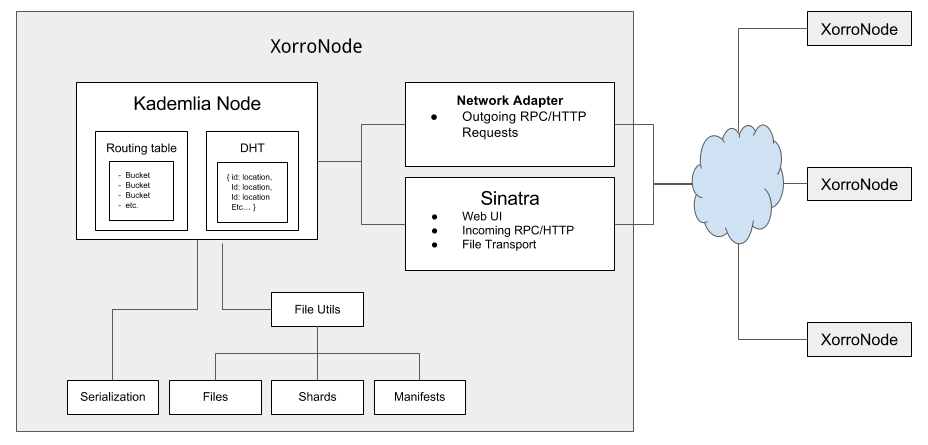
The top level object is XorroNode, which is a modular Sinatra application
Each XorroNode contains:
- a single Kademlia Node, responsible for maintaining its own routing table and DHT
- A network adapter for initiating RPC calls to other nodes.
- A Sinatra endpoint for receiving RPC from other nodes, web UI, and file transport.
- File Utilities for file ingest, sharding, and manifest creation.
Future Work
While Xorro P2P's Alpha release is functional P2P software, there are still many improvements we want to make! Below are some of our plans..
Replace HTTP with TCP/UDP based RPC and File transport
Using HTTP for RPC and file transport allowed us to leverage pre-existing tooling, and focus our development efforts on problems more specific to the Kademlia DHT. However, a TCP/UDP based approach would allow us to reduce overhead, as well as work towards solving NAT traversal issues.
File Submission Outside of Web UI
We really like our web UI, but the current workflow for adding a file to the network could use some work.
Files shared onto the Xorro network are added to a node via browser drag & drop, which is a bit limiting. The browser must submit a POST request to an HTTP route on the local machine with all of the file data in the request body. The local HTTP server receives the data, writes it out, then shards it.
We plan on re-architecting this workflow so that files can be manually added to a local folder, and the sharding/sharing process is kicked off automatically. Furthermore, a native client application or command line tool would further help to streamline file ingest and retrieval.
Conclusion
We hope you enjoyed reading about Xorro!
All of us are available for new opportunities, so please feel free to reach out!
 Ken Chen
Ken Chen David Kurutz
David Kurutz Terry Lee
Terry Lee